비순차적 실행은 CPU가 명령어들을 CPU에 넣어지는 순서가 아닌 다른, 더 효율적인 방법으로 실행하는 것입니다.
예를 들어
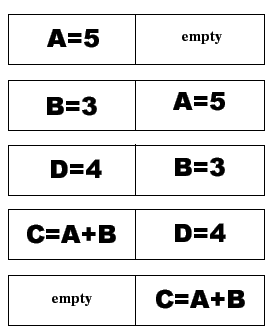
A = 5
B = 3
C = A + b
D = 4
라는 코드가 있을 때, 순차적 실행을 하게 되면

C = A + B 명령 위에 한 사이클 빈다는 걸 알 수 있습니다. 그래서 비순차적 실행을 적용시켜 다른 코드에 종속성이 없는 코드를 먼저 실행하게 해 성능을 끌어올립니다.
예를 들어, 값 A는 CPU의 캐시에 있고, 값 B는 없어서 메모리를 읽어와야 하는 상황일 때
var c = B;
var d = A;
위와 같은 코드를 만난다면
순차적 처리의 경우
- 값 B를 캐시에서 찾음
- 캐시 미스가 발생하고 값 B를 메모리에서 읽어 옴
- 값 c를 할당한 뒤, 메모리에서 읽어 온 값 B로 초기화 (이 과정에서 값 A가 캐시에서 사라짐)
- 값 A를 캐시에서 찾음
- 캐시 미스가 발생하고 값 A를 메모리에서 읽어 옴
- 값 d를 할당한 뒤, 메모리에서 읽어 온 값 A로 초기화
비순차적 처리의 경우
- 값 B가 필요한 코드를 만났지만 캐시 미스라 일단 대기
- 값 A가 필요한 코드를 만났고 캐시 히트
- 값 d를 할당한 뒤, 캐시 히트한 A로 초기화
- 값 B를 메모리에성 읽어 옴
- 값 c를 할당한 뒤, 메모리에서 읽어 온 값 B로 초기화
로 실행하게 됩니다.
비순차적 실행에 필요한 개념
명령어 수준 병렬성(Instruction Level Parallelism, ILP): 명령어 수준에서 종속성으로 엮여있지 않아 병렬적으로 작업
1. 명령어 윈도
명령어 스트림 속에서 윈도 크기만큼의 범위 내에서 ILP를 검사하여 비순차적으로 처리합니다. 처리가 끝나면 가장 오래된 명령어가 윈도에서 빠지고 동시에 새로운 명령어 하나가 추가되어 반복합니다.

- 1. 명령어 하나가 명령어 윈도우 속으로 들어온다. 이와 동시에 제일 오래된 명령어 하나는 완료되어 빠져나간다.
- 2. 명령어 윈도우 내에서 명령어들을 처리한다. (의존성 체크, 스케줄링 후 병렬 실행, 이전 명령어 완료 기다림, …)
- 3. 명령어 윈도우 내에서 가장 오래된 명령어가 빠져나가고, 동시에 다른 명령어가 들어온다.
이를 수치화할 수 있는데 만약 4 개의 명령어가 모두 의존성으로 묶여있다면, 4 개 명령어를 4 cycle에 처리할 수 있다고 하여 ILP = 4 / 4 = 1이라고 말합니다. 반면, 2개씩 명령이 의존성으로 묶여있어 4 개의 명령을 2 cycle에 처리할 수 있다면 ILP = 4 / 2 = 2라고 수치화할 수 있습니다. 의존성이 서로 아무것도 없는 명령들이라면 ILP 값은 4 가 되겠네요.
2. 가짜 의존성 제거(Register Renaming)
가짜 의존성이라는 것은 코드에 사용된 레지스터를 보면 의존적인 것처럼 보이지만, 실제로는 의존성이 존재하지 않는 경우를 말합니다.
- Read After Write (RAW): 진짜 의존성
- Write After Write (WAW): 가짜 의존성
- Write After Read (WAR): 가짜 의존성
add r1, r1; -> add F1, r1 (가)
add r2, r1; -> add F2, F1 (나)
add r1, r2; -> add F3, F2 (다) @ r1 은 (가)와 의존성 없으므로 F3으로 변경 (WAR)
add r1, r3; -> add F5, F4 (라) @ (가)와는 의존성 없으나 (마)와 의존성 존재 (WAW)
add r4, r1; -> add F6, F5 (마) @ (라)와의 의존성 고려하여 F5로 변경 (RAW)
위 코드를 보면, (다) 명령과 (라) 명령은 마치 r1 때문에 (가) 명령과 의존성이 있는 것처럼 보이는데 (다)와 (라)는 r1 레지스터에 쓰기만 할 뿐 읽진 않으므로 가짜 의존성이 됩니다. 그래서 사용하지 않는 다른 레지스터로 변경할 수 있지만, 뒤에 오는 레지스터에서 사용하는지 확인해야 합니다.
이렇게 의존성 체크 과정에서 가짜 의존성이 발견되어 레지스터의 이름을 바꾸어주는 과정을 Rester Renaming이라고 부릅니다.
두 부류의 레지스터 파일을 이용해서 프로그래머가 모르는 채로 내부적인 레지스터의 변경 작업을 하기 위해, 양쪽 레지스터 간의 매핑 관계를 어딘가에 기록해둡니다. 기록을 해두면 이미 사용한 물리 레지스터를 다시 사용하지 않을 수 있고, 선후 명령어 간의 의존성 검사도 잘할 수 있습니다.
논리 레지스터와 물리 레지스터의 매핑 정보를 유지하는 장소를 RAT(Register Alias Table)이라고 부릅니다.
3. 동적 명령어 스케줄링(Reservation Station)
피연산자(operand)가 준비되기를 기다리기 위해 잠시 저장해두는 곳이 Reservation Station이라는 Queue입니다.
- Operand 준비됐으니 실행 -> Wake-up
- 이제 실행하면 되니까 일 안 하는 실행 장치 찾기 -> Select
Wake-up 작업은 어떤 선행 연산이 끝나서 피연산자가 준비가 됐는데, Reservation Station에서 기다리는 어떤 명령어가 이 피연산자를 기다리고 있었나 찾는 것을 말합니다. 이것을 찾으려면 매번 Reservation Station Queue에 있는 명령어들이 필요로 하는 피연산자들을 모두 체크하게 됩니다. (병목 지점)
Select 작업은 위에 말한 대로 피연산자가 준비되어 실행 가능한 상태의 명령어보다 사용 가능한 실행 장치의 숫자가 적은 상황이 있을 수 있으므로 이러한 실행 장치의 할당을 효과적으로 수행할 수 있도록 스케줄링하는 것을 말합니다. (병목지점)
이러한 병목 현상과 복잡성 때문에 Reservation Station Queue의 크기를 무작정 늘려서 병렬성을 높이는 작업에 한계가 있습니다.
결국 Reservation Station 이 존재함으로 해서 명령어들의 실행이 반드시 순차적이지 않고, 피연산자가 준비된대로 비순차적으로 스케줄링되어 실행이 가능한 것입니다.
4. 순차적 완료(Re-order Buffer)
위에서 봤듯이 명령어의 실행은 비순차적일 수 있고 결과도 비순차적으로 나올 수 있으며, 명령어 병렬화로 순서가 섞여서 끝났어도 결과적으론 원하는 순서대로 결과를 보여주는 과정이 필요하고, 비순차적인 결과를 순차적으로 만드는데 Re-order Buffer 가 사용됩니다.
Re-order Buffer 에 결과들을 모아뒀다가 원래의 프로그램 순서대로(In-order) 데이터 Commit 을 해줍니다.
그렇게 하기 위해서 Re-order Buffer 에 끝난 순서대로 넣는것이 아닌, Reservation Station에서 Issue 되는 시점에서 Entry를 할당받아 원래 순서대로 넣습니다.
실행이 다 완료되면 끝난것들만 표시해두고, 처리가 종료 되면 표시가 된 것들 중에서 Reorder Buffer 에서 차례대로 그 결과를 레지스터 등에 Commit 해줍니다.
'해킹 > 과제' 카테고리의 다른 글
| 1. 부트로더, 커널, 파일시스템 (0) | 2021.04.20 |
|---|---|
| 6. 추측 실행(Speculation Execution), 분기 예측(Branch Prediction) (0) | 2021.04.17 |
| 4. 파이프라이닝(Pipelining) (0) | 2021.04.17 |
| 3. CPU의 명령어 처리 구조 (0) | 2021.04.16 |
| 2. 명령어 구조, CPU 구성요소 (0) | 2021.04.16 |